
Table of Contents
Do not index
In the rapidly expanding universe of data, finding the right information at the right time can be like searching for a needle in a digital haystack. ChatBees Serverless Retrieval-Augmented Generation (RAG) is a new service designed for businesses that need to access, interpret, and utilize the wealth of knowledge scattered across various data sources. Built on a robust serverless architecture, it provides a scalable and intelligent solution for information retrieval and response generation. ChatBees is designed from the ground up to be a simple, cost-effective, and easy to maintain solution for developers, support teams, SREs, and customer support teams.
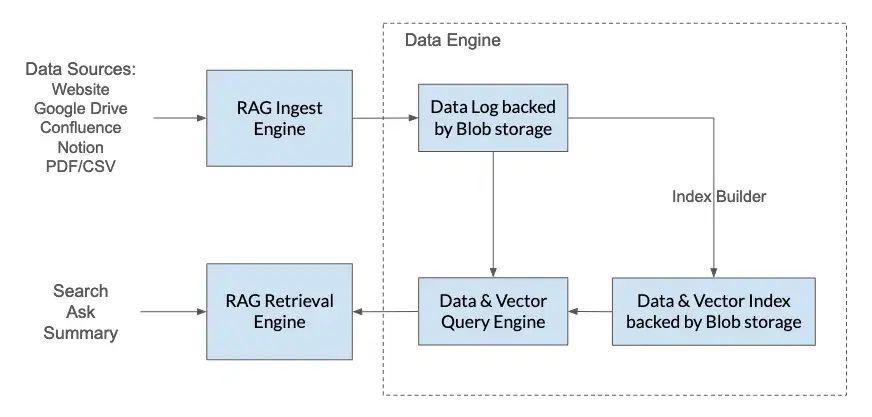
How Does It Work?
The architecture of ChatBees includes three key components: the Intelligent Ingest Engine, the Data Engine, and the Intelligent Retrieval Engine. All components are constructed using a serverless architecture.
Intelligent Ingest Engine
The Ingest Engine seamlessly integrates with Website, Google Drive, Confluence, Notion, and numerous text-based formats such as PDF, CSV, DOCX, MD and TXT files. The engine transforms the data into a structured format that is both searchable and understandable by machines. It generates embeddings, or vector representations of the data, facilitating the execution of complex queries with notable accuracy and speed. The ingest engine is designed to be dynamic and enables continuous data ingestion for operations teams
Data Engine
Once the data is ingested, it is logged and stored in a secure Blob storage. The Index Builder loads the data logs and creates indices for the data and vector embeddings. These indices are crucial for enabling quick retrieval, helping the service to find the most relevant information efficiently. The data and vector indices are also stored in the secure Blob storage. The vector engine is developed by ChatBees and enables a scalable, secure vector store that is able to retrieve data efficiently.
By storing all data in Blob storage, ChatBees achieves dynamic scalability of compute resources and becomes full serverless. The engine includes a Caching layer, which stores frequently accessed data to decrease latency and enhance response times for common queries, providing users with quick answers.
Intelligent Agentic Retrieval Engine
The Retrieval Engine is a key component to ChatBees service. It processes user requests and retrieves the appropriate data and vector embeddings. It is an agentic framework that applies techniques including auto-tuning, auto-reranking, etc, to identify and retrieve the most relevant information based on the query and embeddings. We use reflection techniques to auto-tune the output. This self-improving mechanism ensures that the service becomes smarter and more efficient with each query it processes.
Seamless Serverless Experience
The serverless nature of ChatBees RAG simplifies infrastructure management for users, eliminating concerns about server setup, scalability, and maintenance. “ChatBees enabled me to search internal content without DevOps in minutes” quoted by an early customer who has deployed the service for their internal operations teams. This results in cost savings, enhanced scalability, and allows users to concentrate on application development without backend worries.
ChatBees RAG aims to deliver more than just information retrieval; it strives to understand the context and nuances of user queries. By applying advanced AI and machine learning techniques, it provides answers that are both accurate and highly relevant, tailored to the specific requirements of each user.
For businesses interested in incorporating advanced search functionalities into their applications or services, ChatBees offers an accessible, scalable, and intelligent solution. Suitable for various applications such as customer service, data analysis, or content management, ChatBees RAG is designed to enhance capabilities and optimize the use of data.